大數(shù)據(jù)技術之高頻面試題 數(shù)據(jù)處理技術的技術開發(fā)深度解析
在當今數(shù)據(jù)驅動的時代,大數(shù)據(jù)技術已成為企業(yè)核心競爭力之一。在招聘大數(shù)據(jù)技術開發(fā)崗位時,數(shù)據(jù)處理技術是面試官考察的核心領域。本文將深入解析數(shù)據(jù)處理技術開發(fā)相關的高頻面試題,旨在幫助求職者系統(tǒng)梳理知識體系,掌握核心要點。
一、 數(shù)據(jù)處理流程核心概念
- 數(shù)據(jù)采集與接入
- 高頻問題:請簡述Flume、Kafka、Sqoop等數(shù)據(jù)采集工具的原理、適用場景及區(qū)別。
- 技術要點:
- Flume:基于流式架構的日志采集、聚合和傳輸系統(tǒng),核心概念包括Agent、Source、Channel、Sink。面試常考其可靠性保證(如Channel的事務機制)和負載均衡策略。
- Kafka:分布式消息隊列,用于構建實時數(shù)據(jù)管道和流式應用。重點理解其高吞吐原理(順序IO、零拷貝)、Topic、Partition、副本機制、生產(chǎn)者/消費者API以及如何保證消息不丟失、不重復。
- Sqoop:用于Hadoop與關系型數(shù)據(jù)庫間數(shù)據(jù)遷移的工具。需掌握其導入導出原理(MapReduce實現(xiàn))、增量導入方式及性能優(yōu)化。
- 數(shù)據(jù)存儲
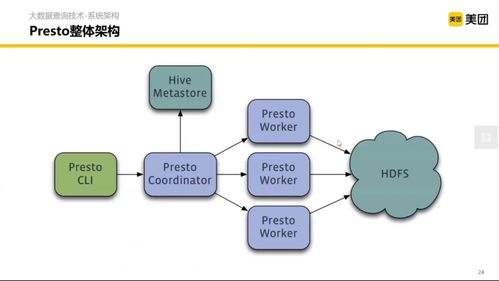
- 高頻問題:HDFS的讀寫流程是怎樣的?HBase的存儲模型與HDFS的關系是什么?
- 技術要點:
- HDFS讀寫流程:需清晰描述客戶端與NameNode、DataNode的交互細節(jié),包括塊的概念、機架感知、副本放置策略。
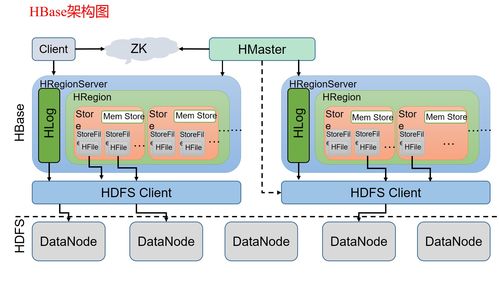
- HBase:理解其基于HDFS的LSM樹存儲結構,RowKey設計原則(避免熱點問題),Region分裂機制,以及如何與MapReduce/Spark集成進行批量數(shù)據(jù)處理。
二、 批處理與流處理框架
- 批處理:MapReduce與Spark Core
- 高頻問題:Spark為什么比MapReduce快?簡述Shuffle過程及其優(yōu)化。
- 技術要點:
- Spark優(yōu)勢:基于內(nèi)存計算的DAG執(zhí)行引擎,減少了磁盤I/O;多階段任務并行,避免了MapReduce重復的序列化與落盤。
- Shuffle:是連接Stage的關鍵環(huán)節(jié),是性能瓶頸。需詳細說明Map端和Reduce端的流程(Combine、Partition、Sort、Spill、Merge)。優(yōu)化手段包括調整緩沖區(qū)、使用ByPass機制、選擇高效的序列化方式(如Kryo)、合理設置分區(qū)數(shù)。
- 流處理:Spark Streaming與Flink
- 高頻問題:對比Spark Streaming的微批處理與Flink的真正的流處理。什么是CEP?如何實現(xiàn)Exactly-Once語義?
- 技術要點:
- 架構對比:Spark Streaming將流離散化為一系列小批量(DStream),本質是批處理;Flink將批視為有界的流,采用事件驅動的流式架構,延遲更低。
- CEP(復雜事件處理):用于在數(shù)據(jù)流中檢測特定事件模式。需了解其基本概念和應用場景(如金融風控、物聯(lián)網(wǎng)監(jiān)控)。
- Exactly-Once語義:是流處理的核心保證。需理解Spark基于WAL和冪等輸出的實現(xiàn),以及Flink基于分布式快照(Checkpoint)和兩階段提交(2PC)的實現(xiàn)原理。
三、 數(shù)據(jù)處理開發(fā)實戰(zhàn)
- 數(shù)據(jù)清洗與質量保證
- 高頻問題:如何處理數(shù)據(jù)中的臟數(shù)據(jù)(缺失、異常、重復)?如何設計數(shù)據(jù)質量監(jiān)控體系?
- 技術要點:
- 清洗策略:根據(jù)業(yè)務規(guī)則進行填充(均值、中位數(shù))、過濾、去重。常用Spark SQL、DataFrame API或UDF實現(xiàn)。
- 質量監(jiān)控:定義完整性、準確性、一致性、及時性等維度指標,通過定時任務進行校驗和告警。
- 性能調優(yōu)
- 高頻問題:遇到一個運行緩慢的Spark/MapReduce作業(yè),你會如何著手排查和優(yōu)化?
- 技術要點:
- 排查步驟:查看作業(yè)執(zhí)行計劃(如Spark的
explain)、監(jiān)控GC情況、分析數(shù)據(jù)傾斜(通過Key的分布)。
- 優(yōu)化手段:
- 資源層面:調整Executor數(shù)量、核心數(shù)、內(nèi)存分配(堆內(nèi)/堆外)。
- 任務層面:使用廣播變量減少數(shù)據(jù)傳輸;對RDD進行持久化(選擇正確的StorageLevel);合理設置并行度。
- 數(shù)據(jù)傾斜處理:使用加鹽(Salt)或兩階段聚合;將傾斜Key過濾出來單獨處理;使用Flink的
rebalance等操作符。
- SQL與編程API
- 高頻問題:Hive SQL優(yōu)化有哪些常見手段?Spark SQL中DataFrame、DataSet、RDD的區(qū)別與聯(lián)系?
- 技術要點:
- Hive SQL優(yōu)化:使用分區(qū)和分桶;選擇適當?shù)奈募袷剑∣RC, Parquet)和壓縮格式;避免笛卡爾積;使用MapJoin處理小表關聯(lián);調整并行度等。
- Spark SQL三劍客:理解RDD(彈性分布式數(shù)據(jù)集,底層API)、DataFrame(以命名列組織的分布式數(shù)據(jù)集,等價于RDD[Row])、DataSet(強類型API,結合了RDD和DataFrame的優(yōu)點)的演進和適用場景。
四、 新興趨勢與架構設計
- Lambda與Kappa架構
- 高頻問題:請描述Lambda架構的組成和優(yōu)缺點。為什么Kappa架構越來越受關注?
- 技術要點:
- Lambda架構:包含批處理層(處理歷史全量數(shù)據(jù),保證準確性)、速度層(處理實時增量數(shù)據(jù),保證低延遲)和服務層(合并視圖)。優(yōu)點是兼顧準確與實時,缺點是維護兩套系統(tǒng)復雜性高。
- Kappa架構:統(tǒng)一使用流處理系統(tǒng),通過重放歷史數(shù)據(jù)來滿足批處理需求。得益于Flink等流處理引擎的成熟,架構更簡潔,但對消息隊列的存儲能力和流處理引擎的回溯能力要求高。
- 數(shù)據(jù)湖與湖倉一體
- 高頻問題:數(shù)據(jù)湖、數(shù)據(jù)倉庫和數(shù)據(jù)湖倉的區(qū)別是什么?
- 技術要點:理解數(shù)據(jù)湖(存儲原始格式數(shù)據(jù),支持靈活分析)、數(shù)據(jù)倉庫(存儲清洗后的結構化數(shù)據(jù),服務于BI)的概念,以及湖倉一體(在數(shù)據(jù)湖上構建數(shù)據(jù)倉庫的管理和性能特性)的融合趨勢及其技術實現(xiàn)(如Delta Lake, Apache Iceberg)。
###
面試中對數(shù)據(jù)處理技術的考察,不僅限于對工具和概念的背誦,更注重對原理的深刻理解、對技術選型的思考以及在真實場景中解決問題的能力。開發(fā)者應深入理解數(shù)據(jù)在系統(tǒng)中的完整生命周期,從采集、存儲、計算到應用,并結合具體業(yè)務需求,構建高效、穩(wěn)定、可擴展的數(shù)據(jù)處理管道。持續(xù)關注流批一體、實時數(shù)倉等前沿方向,將使你在技術浪潮中保持競爭力。
如若轉載,請注明出處:http://www.xiyuangame.cn/product/75.html
更新時間:2026-04-10 09:08:58